Real-Time DSTNet
Overview
此專案對於CVRP 2023的論文Deep Discriminative Spatial and Temporal Network for Efficient Video Deblurring(DSTNet)進行改進。該作品提出了創新的模型架構,用來做影像去模糊的修復,但是原本的work只能在獲取完整時間段的影像後,才能做影像去模糊,並且inference的速度不夠快。
而我們將其改進成Online架構,可以在新的frame進入時,即時做去模糊,並把inference的時間縮短至0.027 frame/s (37 fps),並且建了一個系統來做即時去模糊。
Project Post:

Background
於大一暑期,修習”深度學習(DLP)”之專題
Apporach
Origin Model
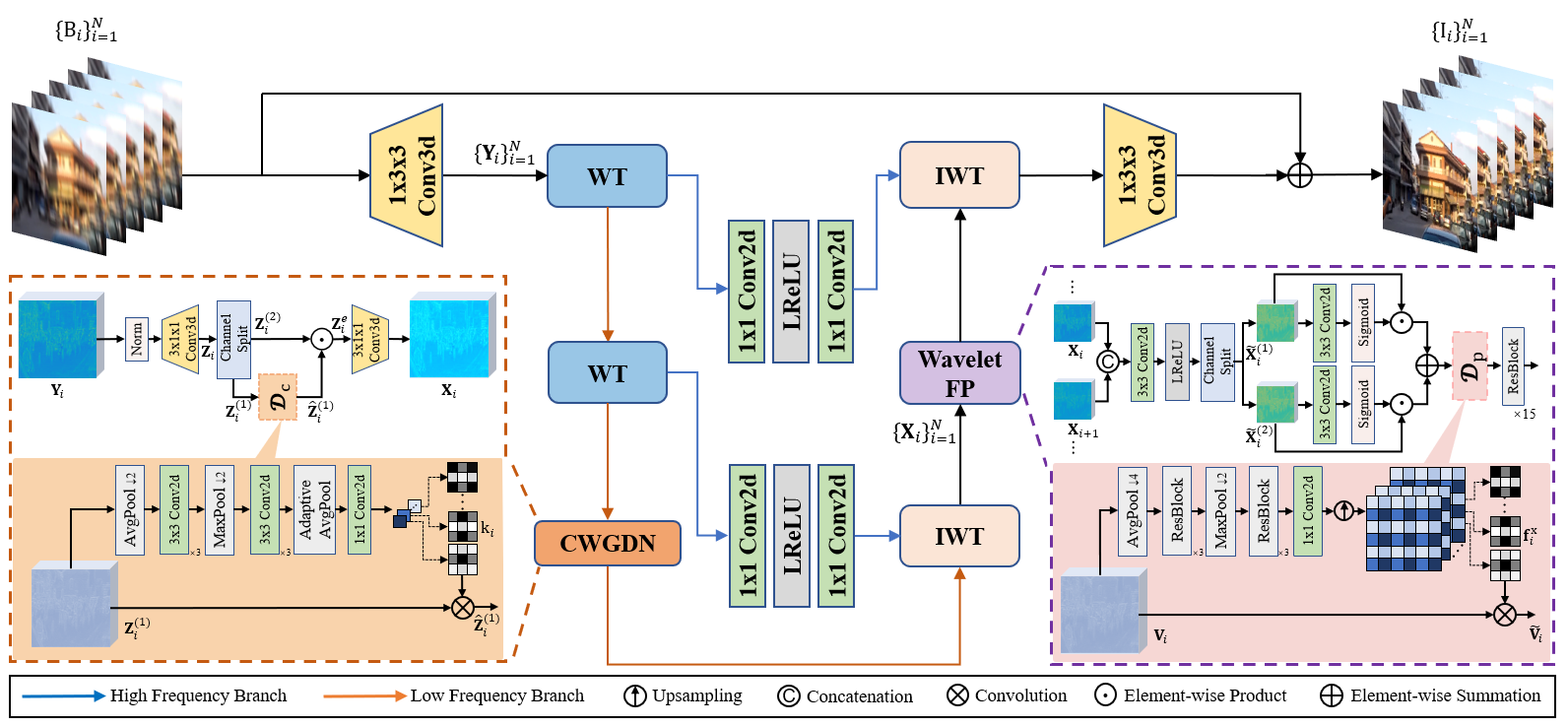
原本的模型架構使用Wavelet Transformation降低圖片解析度,並且使用CNN + RNN的架構,組成CWGDN, DTFF, Wavelet FP三個主要component,用來做時間空間上的資訊融合,並以融合後的資訊去做影像去模糊,達到影像去模糊的SOTA。
Modification
將原本模型架構的Bidirection RNN修改為Unidirection RNN,使其能夠做到Online inference,不需要依賴完整前後文的影片內容。讓他能夠每輸入一個frame就處理一個frame,也降低參數量,讓他的inference速度更快,如圖: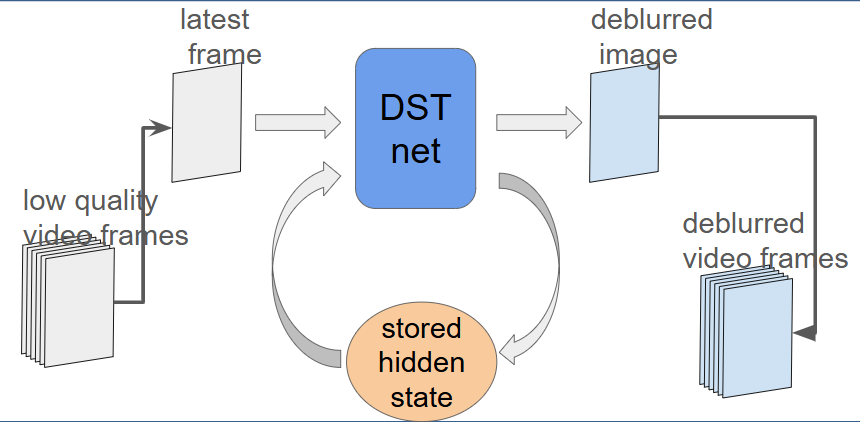
接著,對於原本的model加入一個Encoder,用來做減少參數後的RNN的調校,使其去模糊的表現更好。
整體的model architecture如下: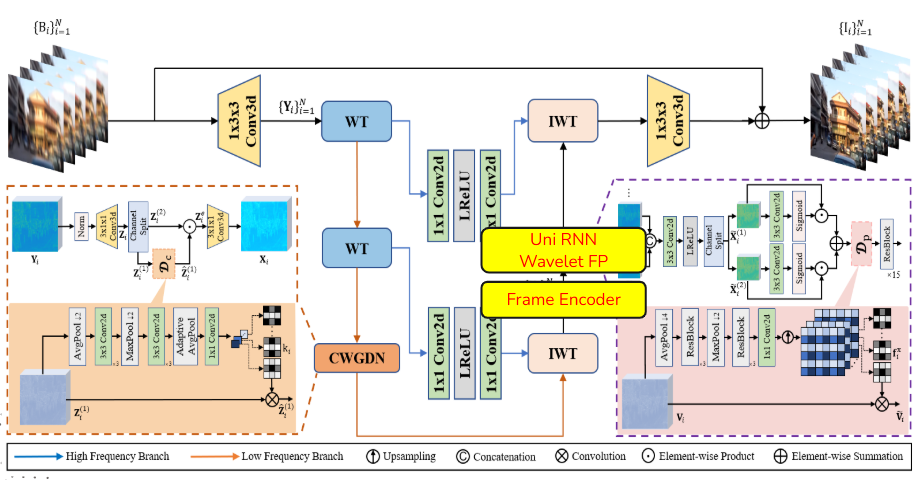
Result
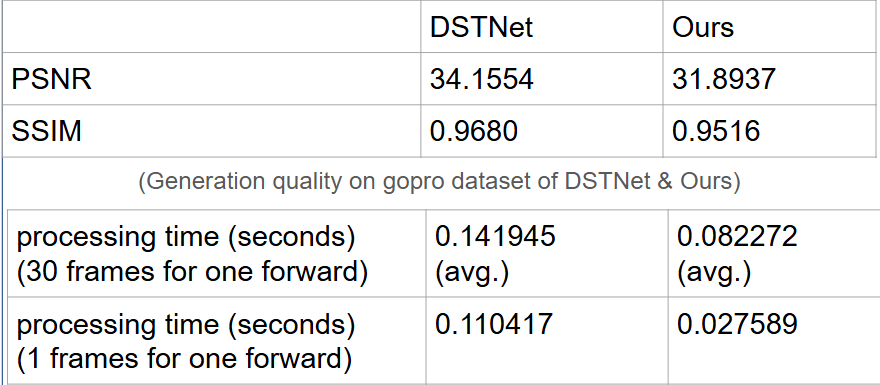
在performance上,犧牲了約2.2點的PSNR,但讓處理單一frame的速度提升到400%,得到了有效果的trade off。
Contribution
我: paper survey、Real-Time DSTNet演算法撰寫、Demo系統撰寫
組員1: paper survey、Real-Time DSTNet的參數測試、DSTNet實驗數據產出
組員2: paper survey
Ohter
本文僅簡單概述Project的部分成果,詳細的內容、分析詳見:
https://github.com/youzhe0305/Real-Time-DSTNet
裡面有完整的程式碼、報告、簡報