LLM輔助論文檢索機器人
Overview
此專案製作”論文綜整與檢索的Discord Bot”。透過selenium爬蟲收集最新的論文並解析其內容。利用RAG LLM技術,以本地資料庫的形式供LLM搜索,讓LLM可以檢索出符合使用者需求敘述且足夠新的論文,最後以discord Bot的方式製作使用者介面,與使用者互動及呈現資料。
CoreTech
- Crawler
- selenium
- LLM
- LangChain
- Discord Bot
示意圖: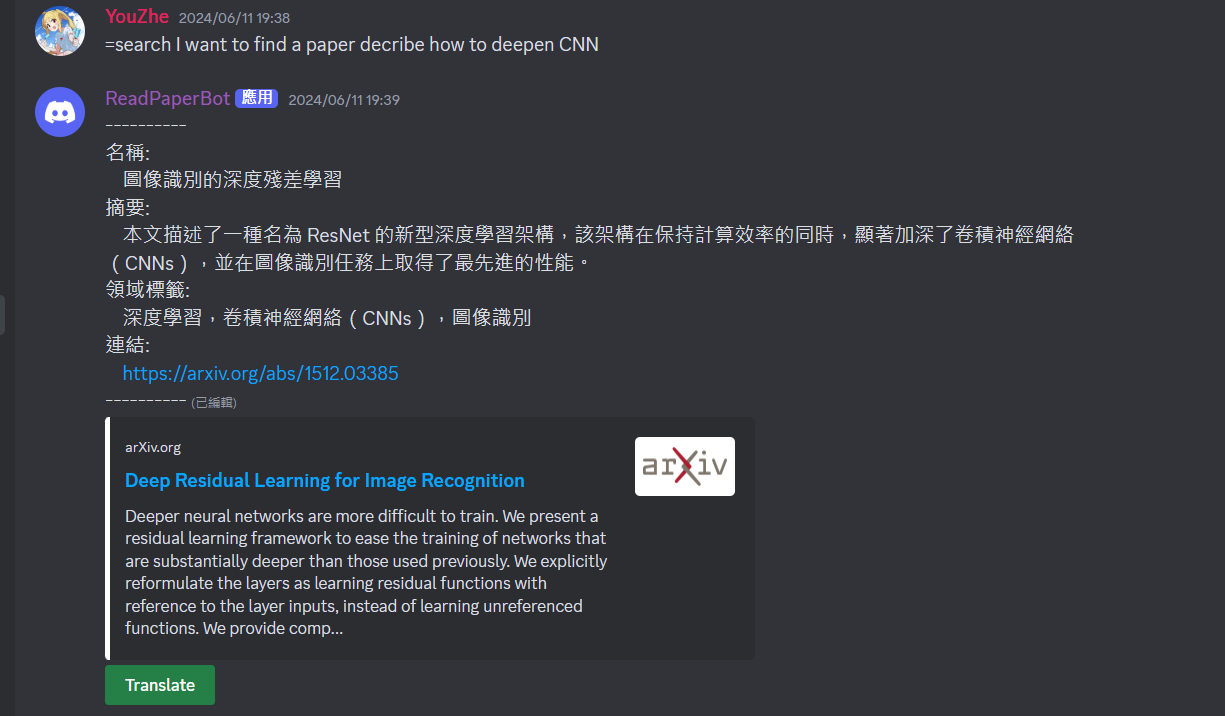
介紹影片:
Background
於大一下學期,修習”人工智慧概論”之專題
因為GPT3.5/4只有到2021/2023的資料庫,不足以供應最新的論文需求,因此製作此程式,用來提供最新論文的搜索。
Apporach
Dataset
使用selenium製作爬蟲,把arXiv網站的2024年論文資料抓下來。目前只抓了title, abstract, link,因為如果存取全文,在搜索及資料庫建置上需要花上非常多的時間以及金錢,故只留下用來搜索的重要部分。
LLM
使用langchain做RAG LLM,採用GPT3.5模型,做了5種prompting enginerring,並另外做了無法搜索成功的例外處理。
使用者輸入任意的關鍵字、問題等,模型將自動將其轉換為搜尋論文的問題,並交由LLM模型在爬蟲得到的資料庫中搜索,回傳英文以及中文的’title, summery, tag, link’。
Discord Bot
使用者介面,使用者可利用指令的方式,給予模型輸入,模型會以Discord Channel Message的方式做出回覆,並且有中英文翻譯的功能。
Result
主要採用3種評估方式: 格式正確率、內容正確率、內容相關率
- 格式正確率: 輸出是否與預期格式相符
- 內容正確率: 內容是否全部正確,沒有編造、錯誤訊息
- 內容相關率: 內容是否與使用者的問題相關
評估結果:
- 格式正確率: 93.3%(28/30)
- 內容正確率: 13.3%(4/30)
- 內容相關率: 96.6%(29/30)
註: 內容正確率中,分析30次試驗發現title、summery、tag都沒有出錯,出錯的部分都是link
Contribution
我: 關於LLM的全部工作,串接LLM與爬蟲、Discord Bot
組員1: 製作爬蟲,爬取資料
組員2: 製作Disocrd Bot介面
Ohter
本文僅簡單概述Project的部分成果,詳細的內容、分析詳見:
https://github.com/youzhe0305/Intro-AI-Final-Project
裡面有完整的程式碼(不含資料庫),以及報告、簡報