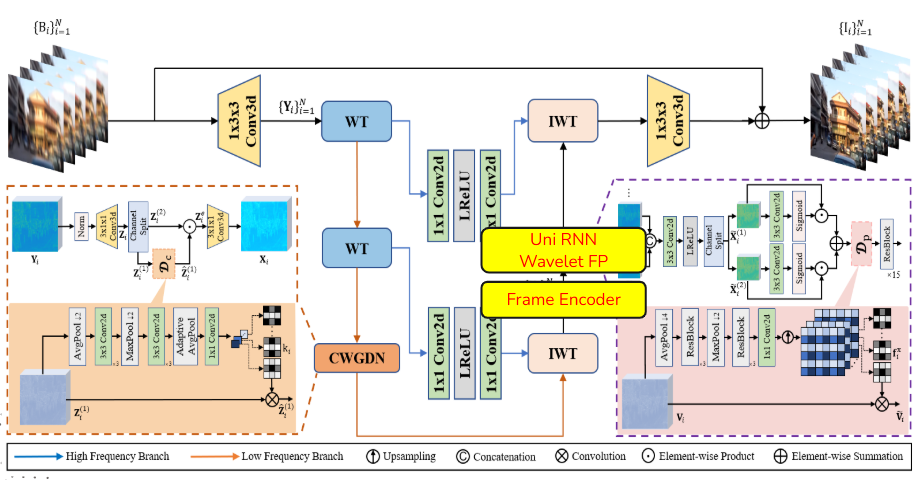
深度學習與實驗(6項project)
Overview
此專案為深度學習課程(DLP)作業,包含以下6個主題及技術
- Handcraft Neural Network
- Backpropagation、Neural Network、numpy
- Iamge Classification
- CNN、SCCNet
- Image Segmentation
- UNet、ResNet
- Conditional Video Generation
- VAE、Video Generation
- Image Inpainting
- Transformer、MaskGIT
- Conditional Image Generation
- Diffusion
Background
於大一暑假,修習”深度學習(DLP)”之作業
LAB
Handcraft Neural Network
在不使用Pytorch、Tensorflow等深度學習套件的情況下,使用Numpy刻出一個神經網路。神經網路的架構圖如下: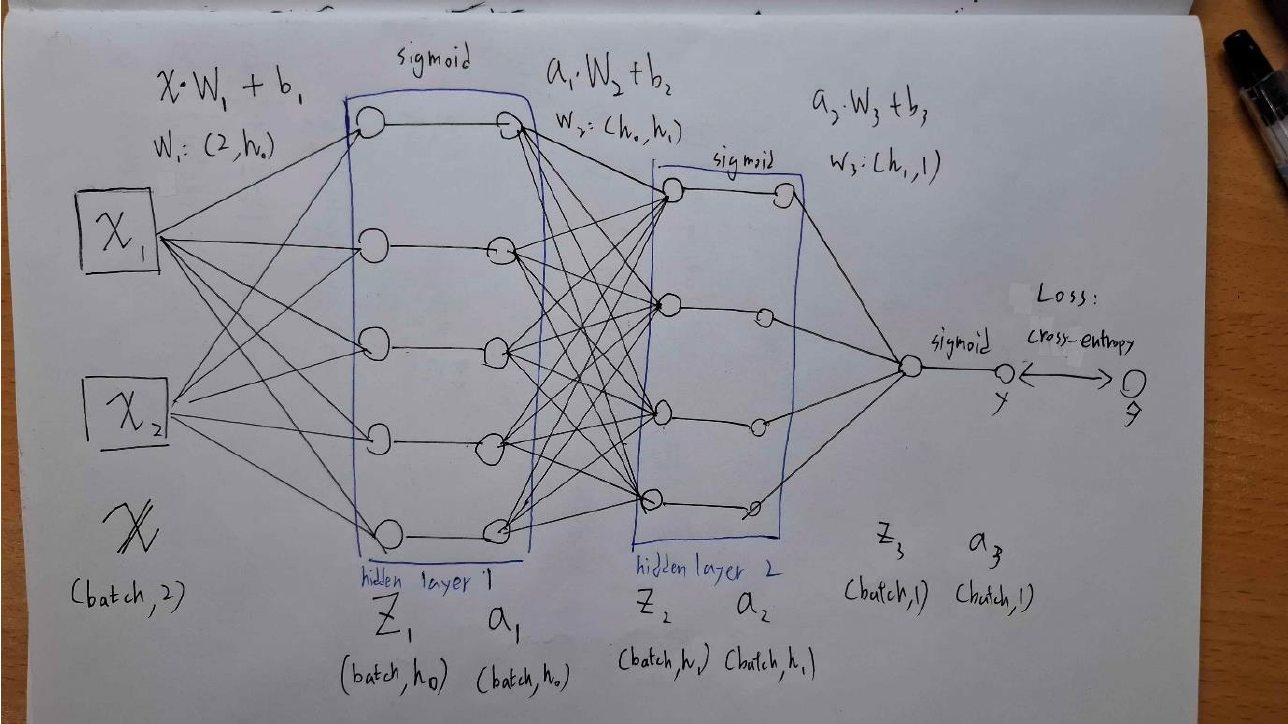
實作基於矩陣的backpropagation,實作梯度的傳播,優化參數,進行資料點的分類
結果如下: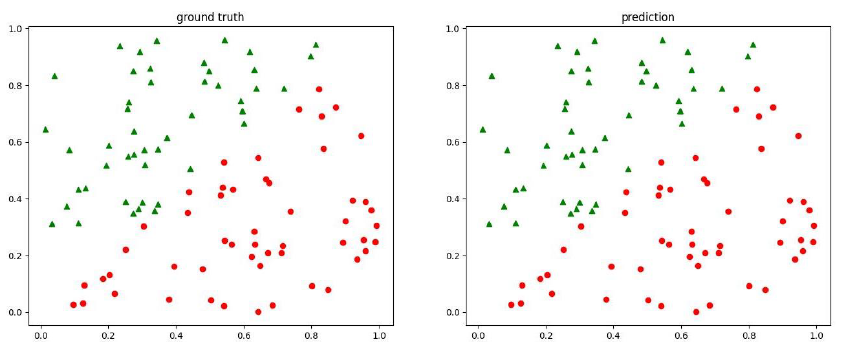
Iamge Classification
構造CNN,用來做基於腦電圖(EEG)的患者動作分類,使用Spatial Component-wise Convolutional Network(SCCNet),網路架構圖如下:
使用Pytorch實作,並且對於一般訓練及Fine-Tune等方式做分析
reference paper: SCCNet
Image Segmentation
只使用Pytorch來構造UNet以及ResNet34-Unet,用來做寵物圖片的前後景image segmentataion,如圖:
建構的網路架構如下:
UNet: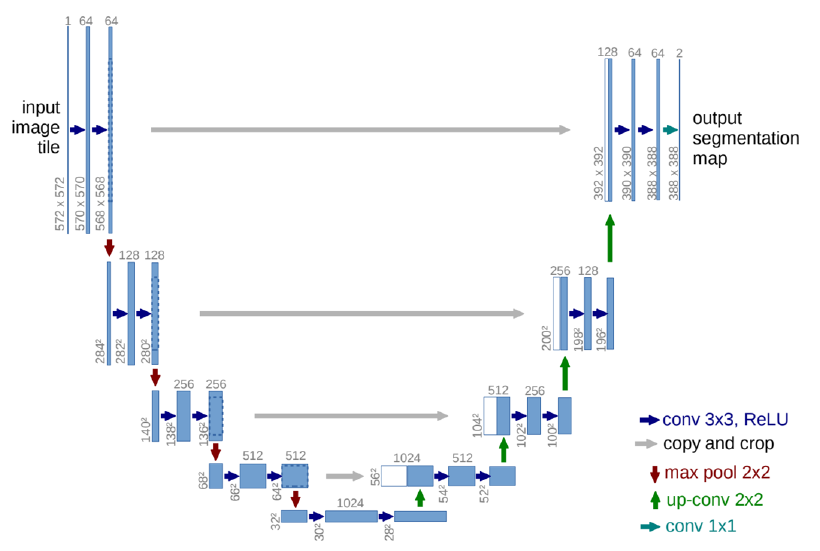
Res34-UNet (以ResNet做Encoder,UNet做Decoder):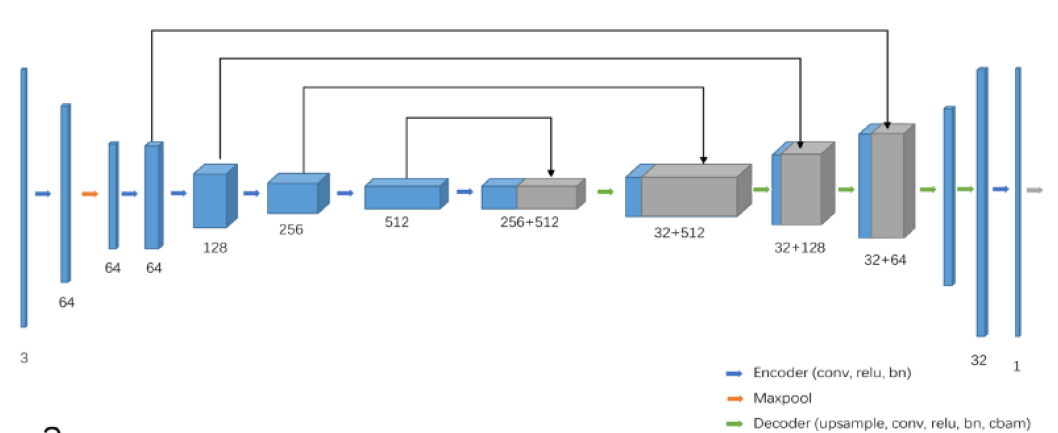
另外也實作不同的Data Augmentation(包括UNet論文中使用的Elastic Transformation等等)
reference paper: UNet、Res34-Unet
Conditional Video Generation
建構Conditional Varitional AutoEncoder (CVAE)模型,用來做圖片的生成
首先,推導出CVAE的objective function:
接著,基於CNN建構出CVAE,模型架構如下: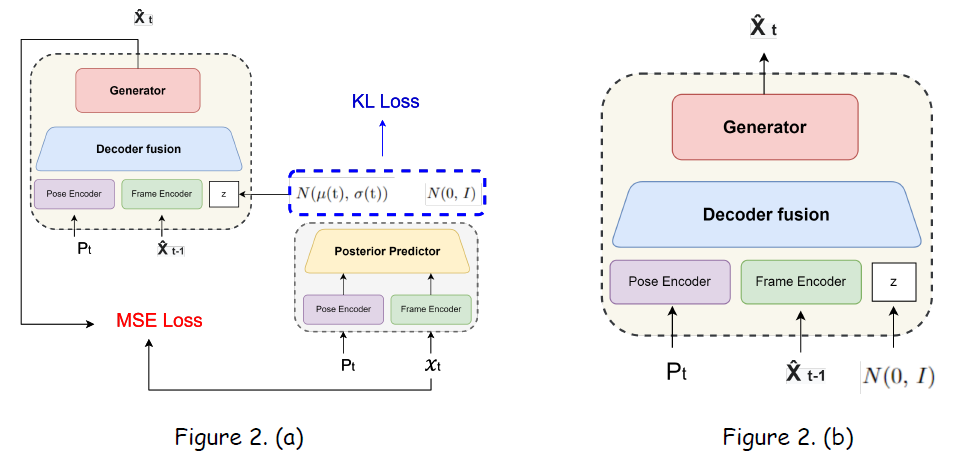
使用CVAE,以肢體骨架圖以及前一幀的影片內容生成影片的下一幀。也就是,在inferece時,可以使用單張frame跟任意數量的骨架圖片生成出一整段的影片
另外,也實作對於loss的adaptive adjustment,這裡實作對於KL Divergence的Annealing。
reference paper: Everybody Dance Now、Stochastic Video Generation with a Learned Prior、Cyclical Annealing Schedule
Image Inpainting
建構基於Transformer的Masked Generative Image Transformer(MaskGIT),可以對於部分有缺漏(被mask住)的圖片的inpainting,如圖:
建構的MaskGIT架構如圖: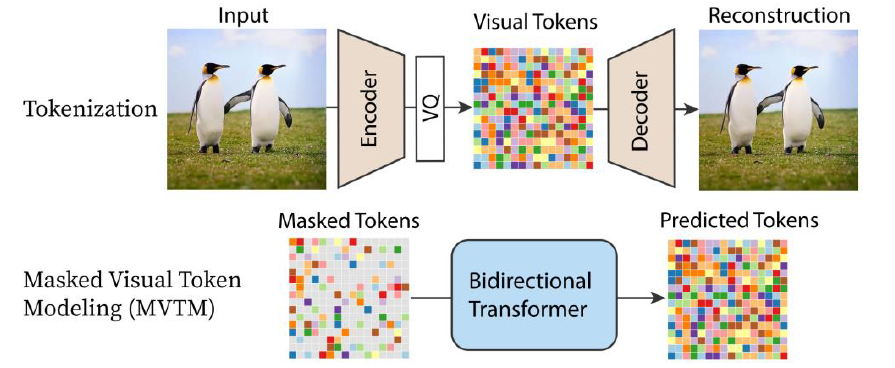
將圖片encode成一張小圖,並且做離散化的Tokenize,限制embedding的可能性,讓模型更容易去model embedding space。接著使用Transformer來做inpainting,把其中的mask token補成其他的token,再用Decoder還原回圖片。
reference paper: MaskGIT
Conditional Image Generation
使用Hugging Face API來建構Diffusion Model及其model pipeline,基於種類的Condition來生成幾何體,如圖:
reference paper: DDPM
Ohter
本文僅簡單概述Project的部分成果,詳細的內容、分析詳見:
https://github.com/youzhe0305/NYCU-DLP
裡面有完整的程式碼及報告